
From Notebook Jail to Production: Scaling LLMs on NVIDIA Blackwell

After finishing my PFE (Final Year Project), I became obsessed with production environments. There is a massive, often painful difference between a model that runs in a Jupyter Notebook and one that actually serves a real-world SaaS application.
Recently, I deployed a production-grade Qwen 3.5 35B MoE model on NVIDIA’s latest Blackwell (GB10) hardware, and I want to share the infrastructure you actually need if you're ready to escape "Notebook Jail."
Why leave the notebook?
Because production requires stability, security, and scalability. When users depend on your platform, you can't rely on a notebook environment that crashes when you look at it the wrong way. You need a robust, enterprise-grade stack.
The Stack Overview
This is the infrastructure I built on the DGX Spark. It’s designed to be modular, fast, and, most importantly, stable.
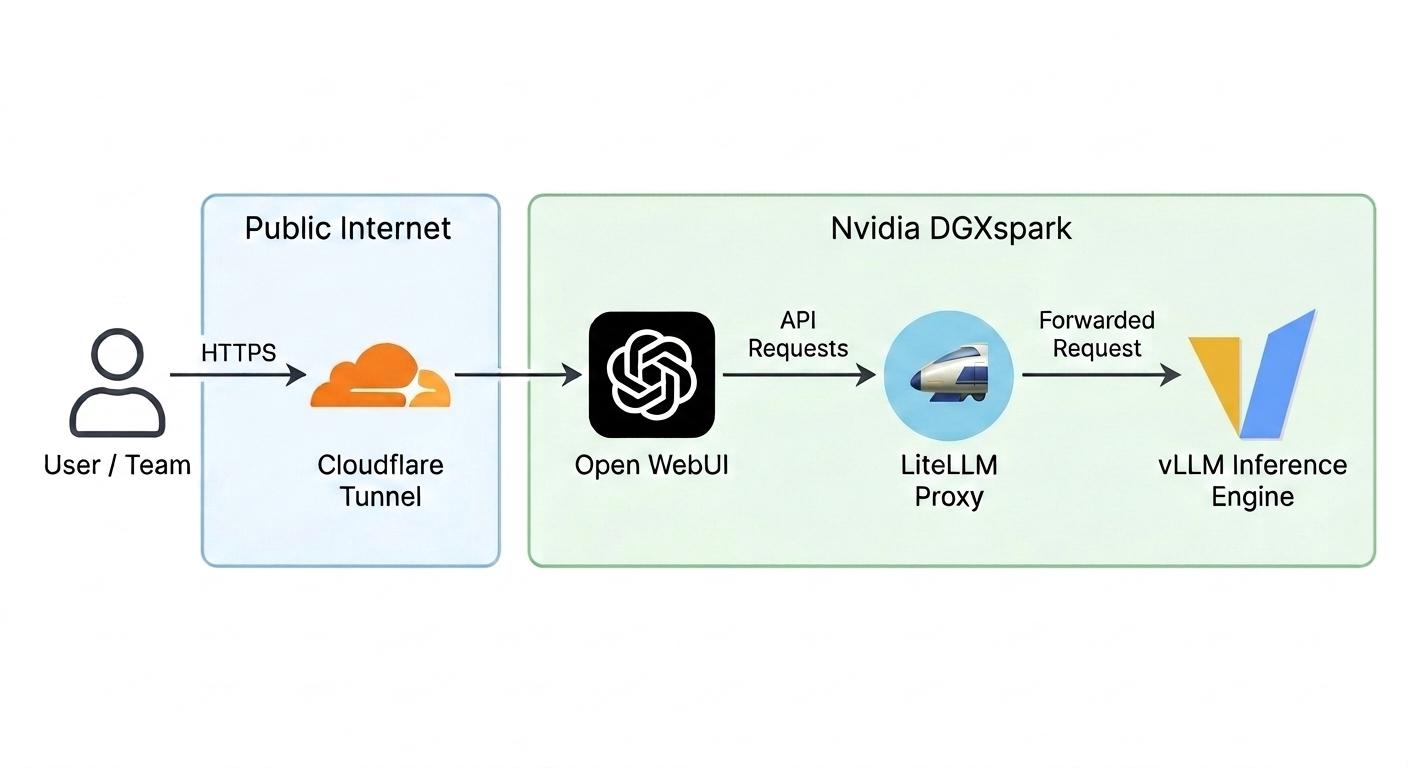
Figure — Infrastructure overview for running Qwen 3.5 35B MoE on NVIDIA Blackwell (DGX Spark).
The Engine (vLLM): There are three major contenders for inference: vLLM, Ollama, and TensorRT-LLM. I’ve tested them all, and I’ve settled on vLLM for production. (Stay tuned—I’m dedicating Blog #3 to why Ollama, while great for dev, isn't always the right fit for high-concurrency production).
The Gateway (LiteLLM): When you’re running multiple models (like Qwen 14B for speed and 35B for reasoning), you need a router. LiteLLM acts as the "brain," managing traffic, API keys, and routing so your frontend doesn't have to change every time you swap a model.
The UI (Open WebUI): We aren't here to reinvent the wheel. We use Open WebUI to provide a polished, enterprise-ready interface that my team can use immediately.
What’s Coming Next?
This is the start of a 5-part series where I’ll break down the architecture, the specific "Blackwell hacks" I had to implement, and how to expose your model securely to your team.
Here is the roadmap:
Blog 1.1: Compiling vLLM from source for Blackwell (The "No Build Isolation" guide).
Blog 2: Orchestrating our production stack with Docker.
Blog 3: The truth about Ollama in Production (and why it's not enough).
Blog 4: Secure Access: Using Cloudflare Tunnels for your AI.
Blog 5: Building a custom Branded Developer Portal.
Are you currently running your models in a notebook, or have you already made the jump to production?
